

El Big Data ¿Es el nuevo oro?
Actualmente los datos se han convertido en un aspecto importante para las empresas, no solo para conocer sus clientes y preferencias, sino también para optimizar sus procesos de negocio y adquirir mejores resultados a través de herramientas de análisis avanzadas.
La recolección de datos y las tendencias que se establecen, hacen posible que las empresas puedan identificar diferentes aspectos de manera veloz y eficaz, generando soluciones en áreas problemáticas que pueden afectar sus compañías a futuro.
En el último año me ha llamado la atención que varias compañías se han encontrado con proyectos de consultoría para construir una bodega de datos, permitiéndoles obtener el máximo provecho a los mismos, ya que los que vienen desarrollando o acaban de implementar no les permiten responder las preguntas del negocio que actualmente necesitan para entender y anticiparse a los cambios del mercado y del consumidor.

El principal obstáculo que enfrentan algunas empresas al modernizar su plataforma de análisis de datos existente, es renunciar a una única base de datos que se está utilizando en su ERP y BI (Business Intelligence) por lo que es difícil ceder después de las cuantiosas inversiones para su desarrollo y operación. En los últimos años he conocido y trabajado con compañías que gastaron millones de dólares y varios años de desarrollo para construir su bodega de datos y los numerosos procesos ETL, fórmulas almacenadas y herramientas de informes que Revisar forman parte de él; por tal motivo es importante comprender los beneficios que trae contar con una sola herramienta a la hora de necesitar un responsable en dar respuestas al negocio con respecto a “¿Dónde están los datos para hacer analytics que necesito?”.
Las empresas que están logrando encontrar beneficio con “analytics” están entendiendo que los datos no deben organizarse entre tablas, o armonizarse para tener el mismo formato, puesto que la armonía no es fundamental para que la DAP (Data Analytics Platform) sea lo suficientemente flexible como para dar resultados.
Por lo tanto, ¿Es conveniente otorgar más inversión en la DAP? La plataforma de datos de la que estamos hablando, es esencial en la transformación digital soportada en AI (Inteligencia Artificial) de cada empresa que quiera mantenerse relevante y competitiva hoy en día, razón por la cual, cada caso de uso analítico debe tener su propio flujo de datos dedicado e independiente, incluso si eso significa que los datos se repliquen docenas de veces y se calculen de manera diferente.
Hay que tener presente que para cada caso de uso se analizan los datos desde un ángulo diferente dependiendo de su necesidad comercial, y eventualmente, esto es desarrollado por un equipo distinto, por este motivo, los análisis de ventas son diferentes a los análisis de marketing o a los análisis de logística.
El error más común cometido por las empresas al intentar hacer analytics, es centrarse en los datos en lugar del problema comercial en cuestión. Consideremos, por ejemplo, una empresa de logística que ha equipado su flota de camiones con tecnología GPS, tal sistema generará datos que muestran los movimientos precisos de cada vehículo, sin embargo lo que la empresa necesita es un análisis de datos que lo ayude a optimizar sus rutas de entrega. Para este problema, necesitamos datos totalmente diferentes, de demanda, de dónde el consumidor está comprando, datos que no son generados por la propia empresa, y niveles de inventario a lo largo del tiempo.
Por ejemplo, en el primer semestre de este año, con el equipo de analytics de una de las CPG más importantes de Colombia, analizamos cómo con los nuevos cambios de comportamiento del consumidor, una tienda que antes de la pandemia tenía una frecuencia de atención diaria, ahora cayó en ventas; se invirtió un presupuesto importante para reactivar la demanda, pero las ventas no reaccionaron positivamente.
Debido a que esta tienda está localizada cerca a centros educativos y oficinas gubernamentales, un consumidor que antes visitaba la tienda 5 o 6 veces por semana y en cada visita compraba un café, ahora solamente la visita 2 o 3 veces por semana, porque ahora puede hacer sus labores diarias de forma digital, por lo tanto, ya no tiene necesidad de desplazarse, entonces, paso de comprar 5 o 6 bebidas a solo 3.
¿Cómo podemos recuperar las otras 3 bebidas que dejo de consumir o donde las está consumiendo ahora? ¿De comprarlas físicamente paso a comprarlas online? En el repositorio de datos que esta compañía desarrolló, se evidenció que no se tenían los suficientes datos para dar respuesta a las preguntas anteriormente mencionadas, por lo que es era necesario buscar datos externos, tales como: Dónde se están generando las compras online, en qué lugares se están moviendo las transacciones digitales para lograr entender los nuevos patrones de compra y consumo, entre otras; nos enfrentamos a un desafío sin data histórica para analizarlo y predecirlo.
Con lo anterior podemos afirmar que no deberíamos usar una sola bodega de datos, ya que con el tiempo limitará nuestra capacidad de aumentar el uso de datos, también debemos aprender, probar y adoptar nuevas herramientas y tecnología, por lo que es importante trabajar este tema con los jefes, en especial con aquellos que se estresan pidiendo todo tipo de métricas o estadísticas y luego no hacen nada con ellas.
A continuación explico el diagrama ilustrado aquí arriba, sobre como debería ser una DAP de fácil implementación y escalabilidad.
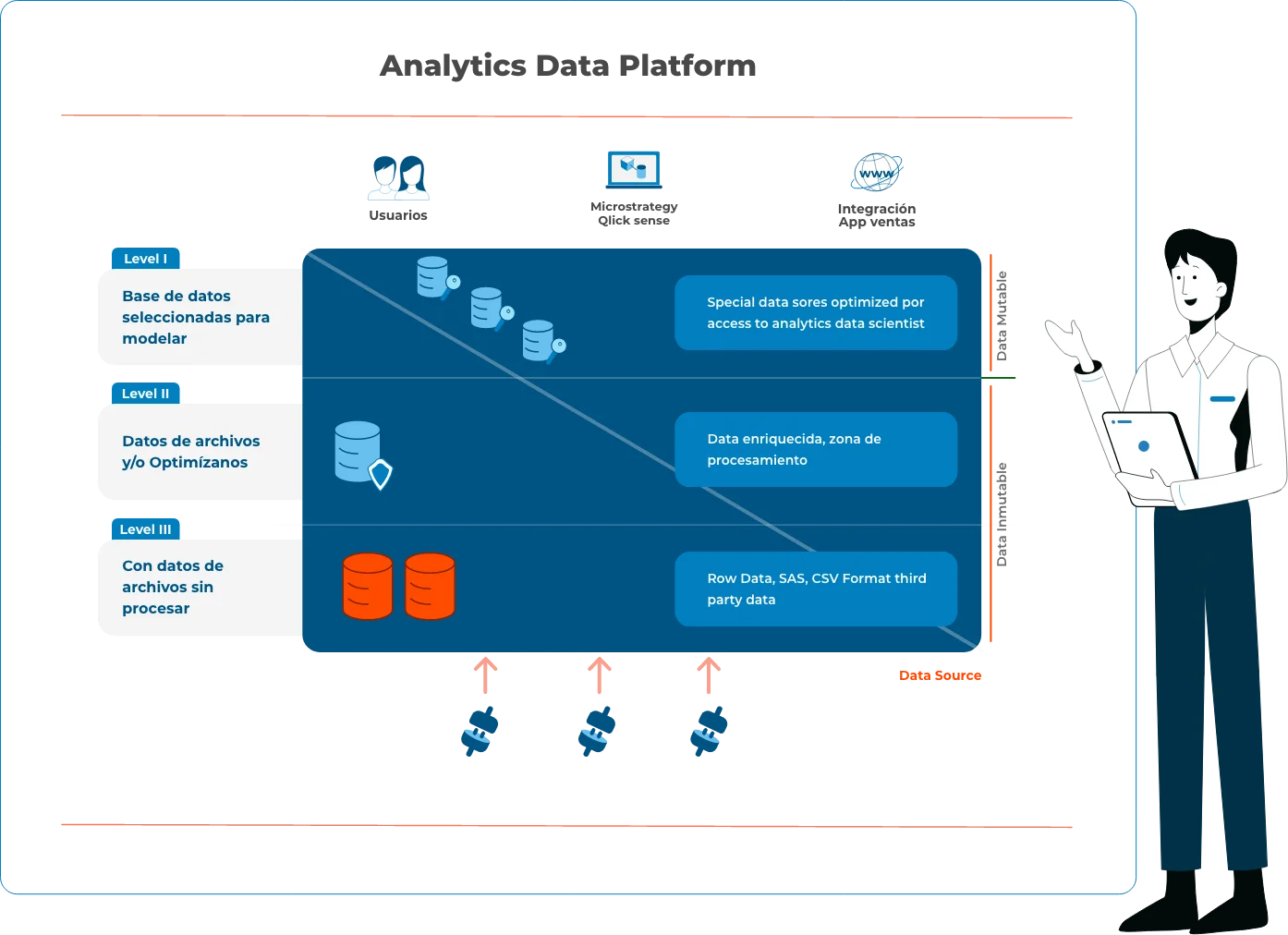
Nivel I (L1): datos sin procesar en almacenamiento de bajo costo.
Todos los datos deben aterrizar en su forma cruda de cada fuente con poca modificación o filtrado, estos pueden provenir de dispositivos IoT, fuentes de transmisión como Kafka o Kinesis, archivos de registro textuales, o interacciones de servicios web, imágenes, videos, comentarios textuales, archivos Excel o CSV de aliados comerciales, o cualquier cosa que desee para analizar y aprender.
Por lo tanto, los datos NO deben organizarse entre tablas, o armonizarse para tener el mismo formato de la dirección o ID del producto, la armonía no es parte del nivel I, y esto es fundamental para que el sistema sea lo suficientemente flexible como para crecer.
Nivel II (L2): Datos de archivos limpios y/u optimizados.
El segundo nivel se construye gradualmente a partir de los datos que entran en el primer nivel. Comienza tan pronto como el archivo aterriza en el primer nivel, y evolucionará a medida que ingresen más y más datos. La evolución se dirigirá en función de la disponibilidad de datos, y principalmente en función del uso comercial que se le dé al análisis de los mismos, como predicciones de Churn o informes BI.
En este nivel es importante tener en cuenta dos aspectos:
Casos de usos múltiples: cada caso de uso analítico debe tener su propio flujo de datos dedicado e independiente. Incluso si eso significa que los datos se replicarán docenas de veces y se calcularán de manera diferente.
Derivados de datos: los datos en el segundo nivel se agregan, filtran o transforman principalmente de su forma original sin procesar para ajustarse a una pregunta de negocio específica. Si necesito predecir las ventas diarias de una marca, no necesito analizar cada compra individual para cada producto único. Puedo ver la agregación diaria y de marca. No debemos tener miedo de hacer que la derivada sea “Demasiado específica”, ya que todavía tenemos los datos sin procesar en el Nivel I. Tendremos muchas otras derivadas específicas para los otros casos de uso comercial. Tener los “mismos” datos en diferentes formas no es un problema, ya que estos no son los mismos datos, sino una derivada de los mismos.
Estos datos es recomendable alojarlos en almacenamiento de bajo costo como AWS S3 o Azure Blob, para poder mantener docenas de “copias” de los datos grandes que poseen las empresas, cada “copia” de esos datos debe tener un costo muy bajo.
Nivel III (L3): Base de datos seleccionada para modelar.
Para permitir las interacciones de los usuarios con los resultados del análisis de datos, a menudo es necesario almacenar en este nivel estos resultados para que puedan ser utilizados por los equipos de trabajo, en términos de velocidad y capacidades de consulta.
Estos datos “limpios” es común almacenarlos en una base de datos relacional (como MySQL o Aurora PostgreSQL), que puede estar bien para conjuntos de datos relativamente pequeños y herramientas de visualización o BI que saben cómo trabajar con las mismas.
Este nivel es mucho más costoso que los dos primeros en términos de almacenamiento de datos y, por lo tanto, se usa solo para los casos de uso reales de los usuarios, y puede ser recreado o eliminado según sea necesario, se tendrá la flexibilidad y la rentabilidad necesarias que se necesita para construir los casos de uso analíticos dentro de su organización. Se necesita tiempo para transformar las empresas para que sean “más inteligentes” y utilicen los datos de manera más eficiente, y esta vez debe planificarse en función de la agilidad, el costo, la escala y la simplicidad.
Operación: Orquestación y Monitoreo
Ejecutar estos 3 niveles, casos de uso múltiples, líneas de negocios múltiples, varias bodegas de datos y otros multiplicadores no es algo que se pueda hacer manualmente con un solo DBA o incluso un equipo de DBA, en muchas empresas, las prácticas de DevOps ya comenzaron a evolucionar, y las capacidades en torno a microservicios, contenedores, integración continua ya están surgiendo.

La migración a la nube también es un interés en algunas empresas y un plan en otras más avanzadas, contribuyendo a democratizar el uso de los datos de parte de IT, sin embargo, la capacidad de hacer DataOps de manera eficiente, es difícil y nueva para la mayoría de las organizaciones. El diseño de una arquitectura ágil y en evolución de la nueva infraestructura debe incluir un aspecto esencial de las habilidades de las personas y la elección de las herramientas adecuadas para automatizar el manejo de los datos en general.
Hoy más que nunca, y en el futuro aún más, la analítica nos muestra el camino para determinar las mejores operaciones. Es decir, “pasar de la economía de la intención a la economía de la acción”, pero ¿cómo puede una empresa extraer el máximo beneficio del ‘analytics’ y qué mitos conviene desterrar sobre este concepto?.
Esta Data Analytics Platform es una parte esencial de la transformación digital y de la inteligencia artificial de cada empresa que quiere mantenerse relevante y competitiva hoy en día, buscar en los datos del pasado no es como manejar el futuro y el problema es que no siempre lo que pasó es lo que se repite, por lo tanto, es difícil predecir cuando algo nace de la nada.